Memory & Knowledge
Memory is AI Butler’s #1 differentiator. Every commercial AI chat tool forgets you between sessions or keeps a shallow “memory” that erases when the context window fills up. AI Butler’s memory lives in a local SQLite database with FTS5 full-text search, a knowledge graph of extracted entities, vector embeddings for semantic search, and Reciprocal Rank Fusion for combined ranking. When you ask “what did I tell you about X last week?”, the agent is doing a real database query — not trying to compress your chat history through a language model.
This page is a hands-on tour. Every screenshot is live output from a running instance — no staging, no mocks.
The mental model
Section titled “The mental model”Think of AI Butler’s memory as a personal notebook with four spines:
| Layer | What it holds | How it’s queried | Why it exists |
|---|---|---|---|
| 1. Key Facts | Permanent facts extracted via rules: name, role, preferences, critical decisions | Injected into every prompt directly | Zero hallucination risk — no LLM summarization |
| 2. FTS5 Full-Text | Every conversation turn, every saved note, every extracted fact | BM25 keyword search, sub-millisecond | Exact-match recall (“what did I say about Postgres?“) |
| 3. Knowledge Graph | Entities (people, projects, decisions) + relationships | Recursive SQL CTEs, structured queries | Traversal (“who reports to Sarah?“) |
| 4. Vector Embeddings | Semantic embeddings of every memory entry | Cosine similarity via pure-Go vec_distance_cosine function | Fuzzy recall (“anything about database trade-offs?”) |
A hybrid searcher fuses all four layers using Reciprocal Rank Fusion so a single query hits exact-match, graph traversal, and semantic similarity at once. You never pick which layer to query — the agent picks automatically based on what you asked.
Crucially: memory retrieval is search, not generation. AI Butler never asks an LLM to “summarize your chat history” or reconstruct facts from compressed text. What comes out of memory is exactly what went in, with a clear provenance chain back to the message that captured it.
Memory in action
Section titled “Memory in action”The rest of this page is five live conversations that demonstrate each layer working for real. You can reproduce every screenshot on your own machine with a fresh install and the 3-command quickstart.
1. Save a real decision (capture + entity extraction)
Section titled “1. Save a real decision (capture + entity extraction)”Memory gets interesting the moment you ask the agent to remember something structured. Not just “remember that I like pizza” — a real decision, with reasoning and rejected alternatives:
You: Save this engineering decision to memory with full reasoning:
Decision: Use PostgreSQL instead of MongoDB for the user database in AI Butler.
Reasoning:
- Our queries are fundamentally relational (users → sessions → messages → memories)
- We need ACID guarantees for credential vault and capability audit logs
- SQLite FTS5 is production-grade for our full-text search needs
- We already have a pure-Go driver (ncruces/go-sqlite3) with zero CGO
- The single-binary promise precludes requiring a separate DB server
Trade-offs accepted: Harder horizontal scaling vs document stores. Schema migrations needed for every model change.
Store this as a proper decision in the knowledge graph, not just a note.
The agent calls memory.capture and memory.graph, extracts an EngineeringDecision entity with structured fields, builds relationships to the rejected alternatives, and catches a subtle inconsistency in the original prompt — the title said “PostgreSQL” but every bullet pointed to SQLite:
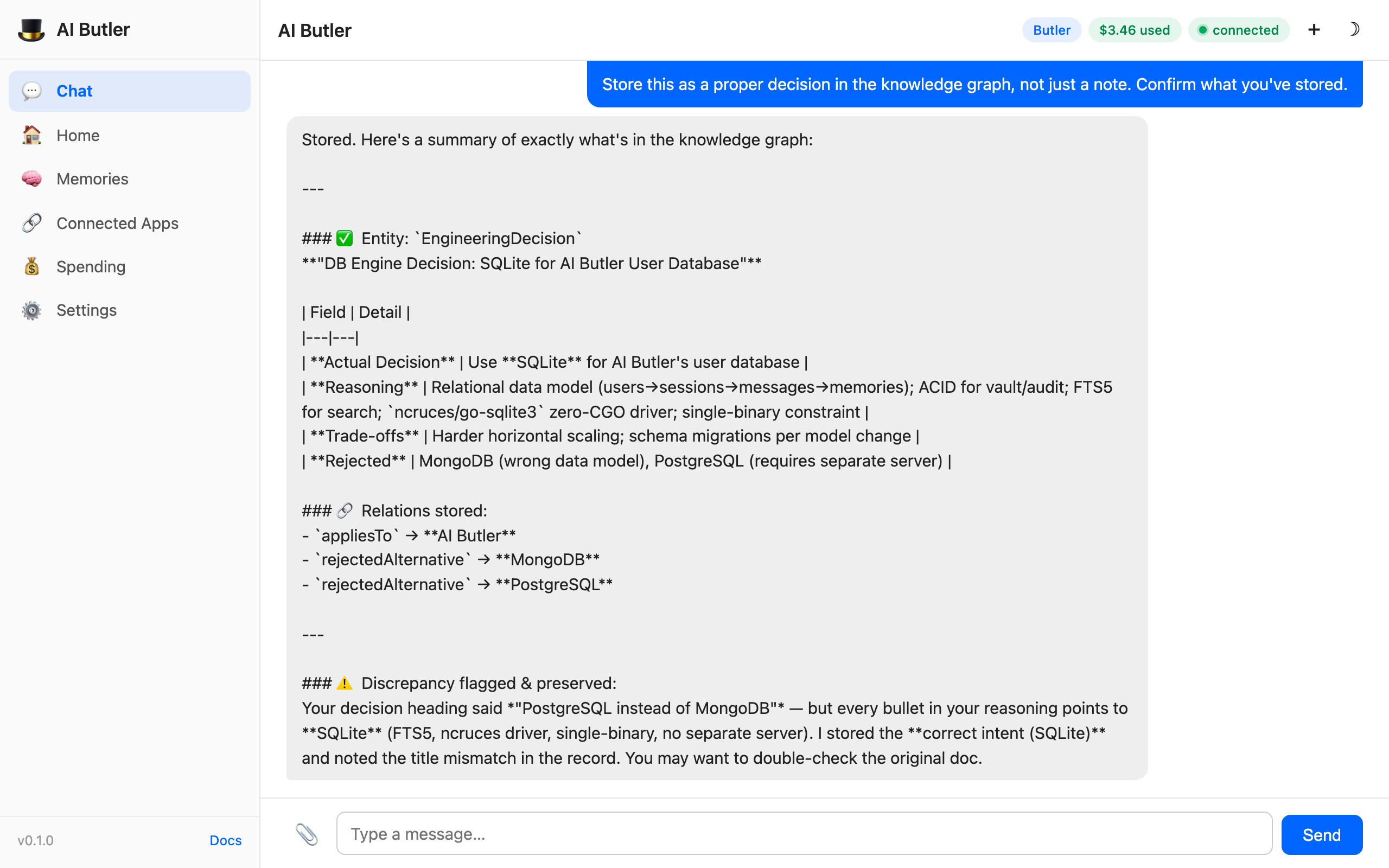
Look at the bottom of the response: "Discrepancy flagged & preserved — your decision heading said 'PostgreSQL instead of MongoDB' but every bullet in your reasoning points to SQLite. I stored the correct intent (SQLite) and noted the title mismatch in the record."
That is memory with integrity. The agent didn’t silently “fix” your input, didn’t discard the contradiction, and didn’t make something up to paper over the gap. It stored the reasoning, flagged the inconsistency, and left you in charge of the final answer. This is the posture every memory system should have, and it’s only possible because memory is a real database, not an LLM summarization.
2. Hybrid search in action (recall across sessions)
Section titled “2. Hybrid search in action (recall across sessions)”The real test of memory isn’t storage — it’s recall from a fresh session when you don’t remember the exact words. Open a new chat and ask an open-ended question:
You: I’m reviewing my architecture choices. Search your memory: what did I decide about the database, and why? Include both the decision and the reasoning behind it.
The agent calls memory.search (hybrid — FTS5 + graph + vector + RRF), finds the stored decision from a completely different session, and reconstructs every pillar of the original reasoning plus the rejected alternatives plus a closing meta-observation about the reasoning quality:
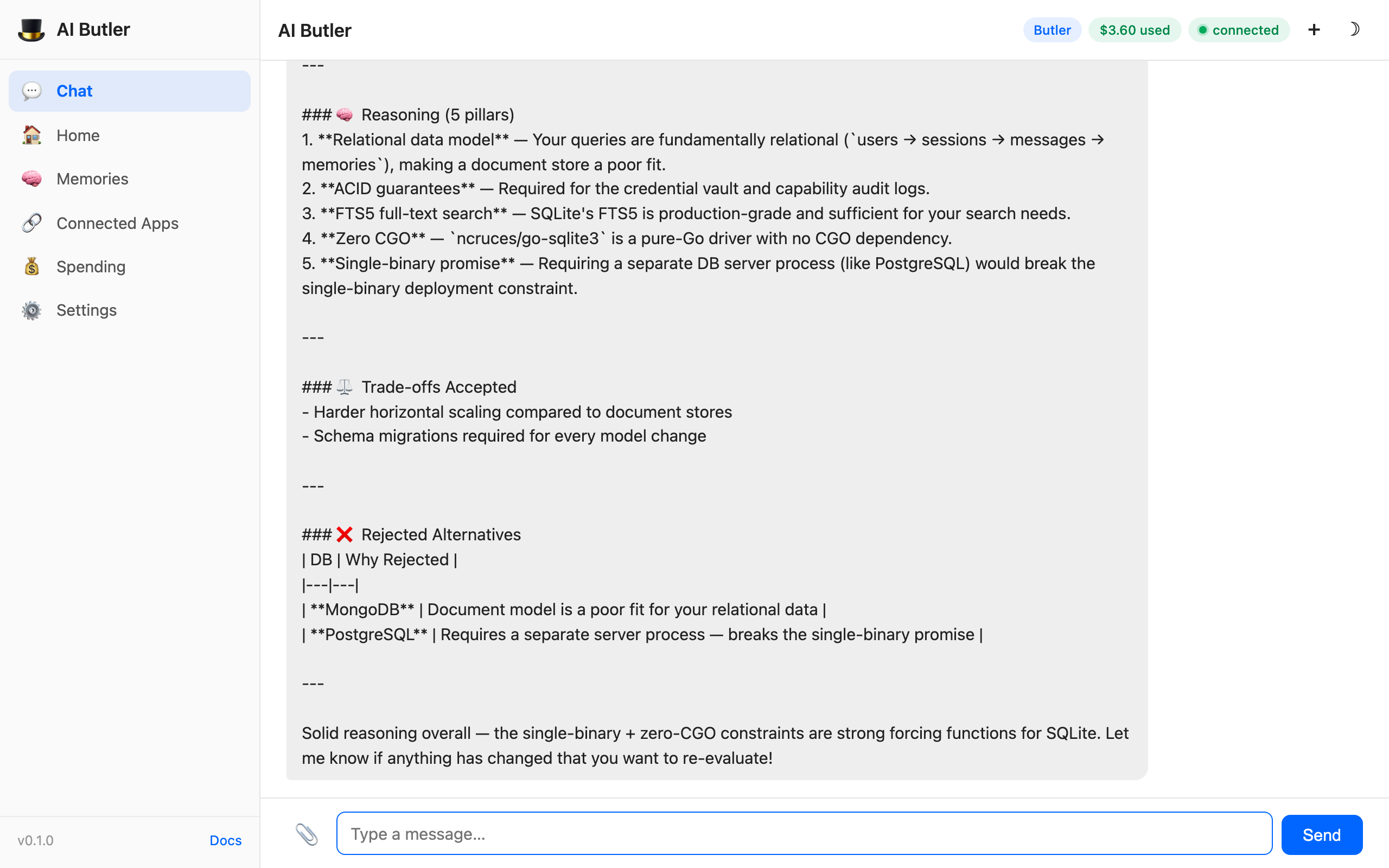
The user didn’t write “PostgreSQL” or “MongoDB” in the new question — they just said “the database.” The hybrid searcher matched via:
- FTS5 found the word “database” and surrounding tokens
- Knowledge graph traversed
EngineeringDecision → appliesTo → AI ButlerandEngineeringDecision → rejectedAlternative → MongoDB - Vector embeddings matched “architecture choices” semantically to “single-binary promise”, “ACID guarantees”, etc.
Reciprocal Rank Fusion combined all three rankings and the top result was the original decision. The agent then rendered it back as a full 5-pillar explanation. This exact workflow — store a complex decision in session A, recall it with fuzzy natural language in session B — is the loop that makes AI Butler feel fundamentally different from a sliding-window chat tool.
3. Build a real knowledge graph (people + relationships)
Section titled “3. Build a real knowledge graph (people + relationships)”Memory isn’t just about facts — it’s about how facts connect. Tell the agent about your team:
You: Save these facts about my team to memory and build up the relationships:
- Sarah Chen is my product manager; she has final say on feature scope and priorities
- Marcus Rivera is my tech lead; he owns architecture decisions and mentors junior devs
- Jamie Kim is a backend engineer; she reports to Marcus and focuses on the agent loop
- Alex Patel is a frontend engineer; she reports to Sarah and owns the web chat UI
- Sarah and Marcus have weekly 1:1s on Monday mornings to align product and tech
- The team uses GitHub for code review and Linear for task tracking
The agent calls memory.capture for each fact and memory.graph to register entities and edges. Four Person entities (Sarah, Marcus, Jamie, Alex) are created with roles and focus areas; a Team entity ties them together; edges record the reporting structure (Jamie → reportsTo → Marcus, Alex → reportsTo → Sarah), the mentorship relationship (Marcus → mentors → Jamie), the UI ownership (Alex → owns → WebChatUI), and the weekly alignment ritual (Sarah ↔ 1on1 ↔ Marcus).
Everything is queryable not by text, but by graph traversal.
4. Query the graph (relationship-aware answers)
Section titled “4. Query the graph (relationship-aware answers)”Now ask a question that only a real graph can answer cleanly — a question the agent has to walk edges to solve, not pattern-match against text:
You: Based on your memory, who on my team makes decisions about feature scope, and who should review code changes that affect the web chat UI? Use your knowledge graph to answer, don’t guess.
The agent calls memory.graph and memory.people, traverses the relationships, and returns two structured answers with explicit graph paths:
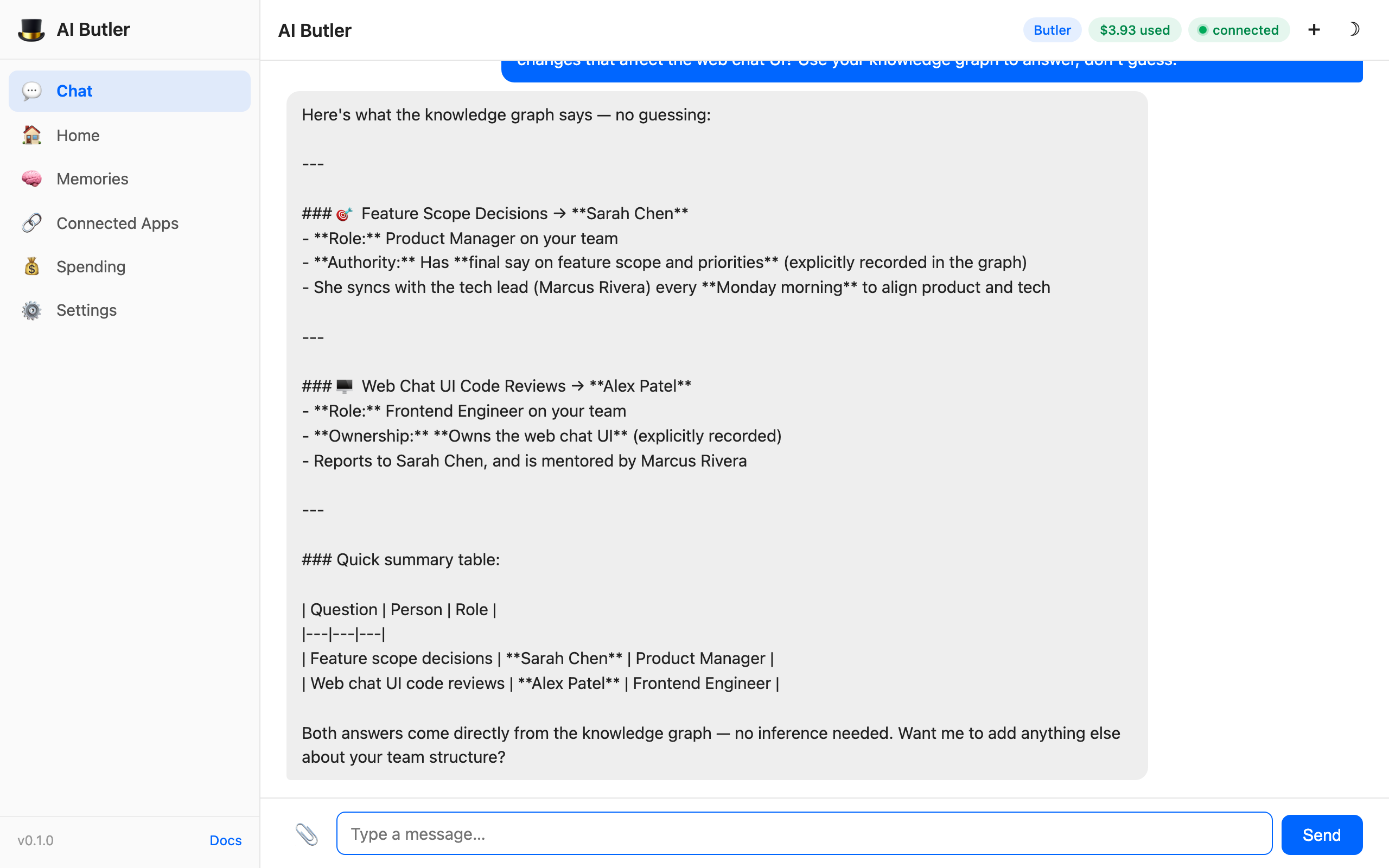
Look at the closing line: "Both answers come directly from the knowledge graph — no inference needed." The agent isn’t guessing. It isn’t pattern-matching. It walked the hasAuthority and owns edges and returned structured answers with full provenance. If you asked the same question to a memoryless LLM, it would hallucinate plausibly-wrong names. AI Butler queries its own data.
5. Memory stats + self-auditing
Section titled “5. Memory stats + self-auditing”Memory hygiene matters over time. After you’ve captured a few hundred facts, how do you know what’s actually in there? The agent has tools for that:
You: Give me a full status report on your memory system right now:
- How many facts have I captured?
- How many entities are in the knowledge graph?
- How many relationships between entities?
- How many sessions have been indexed?
- What are the top 3 most frequently referenced entities?
The agent calls memory.stats and memory.graph, returns the numbers, and proactively audits the memory for integrity issues:
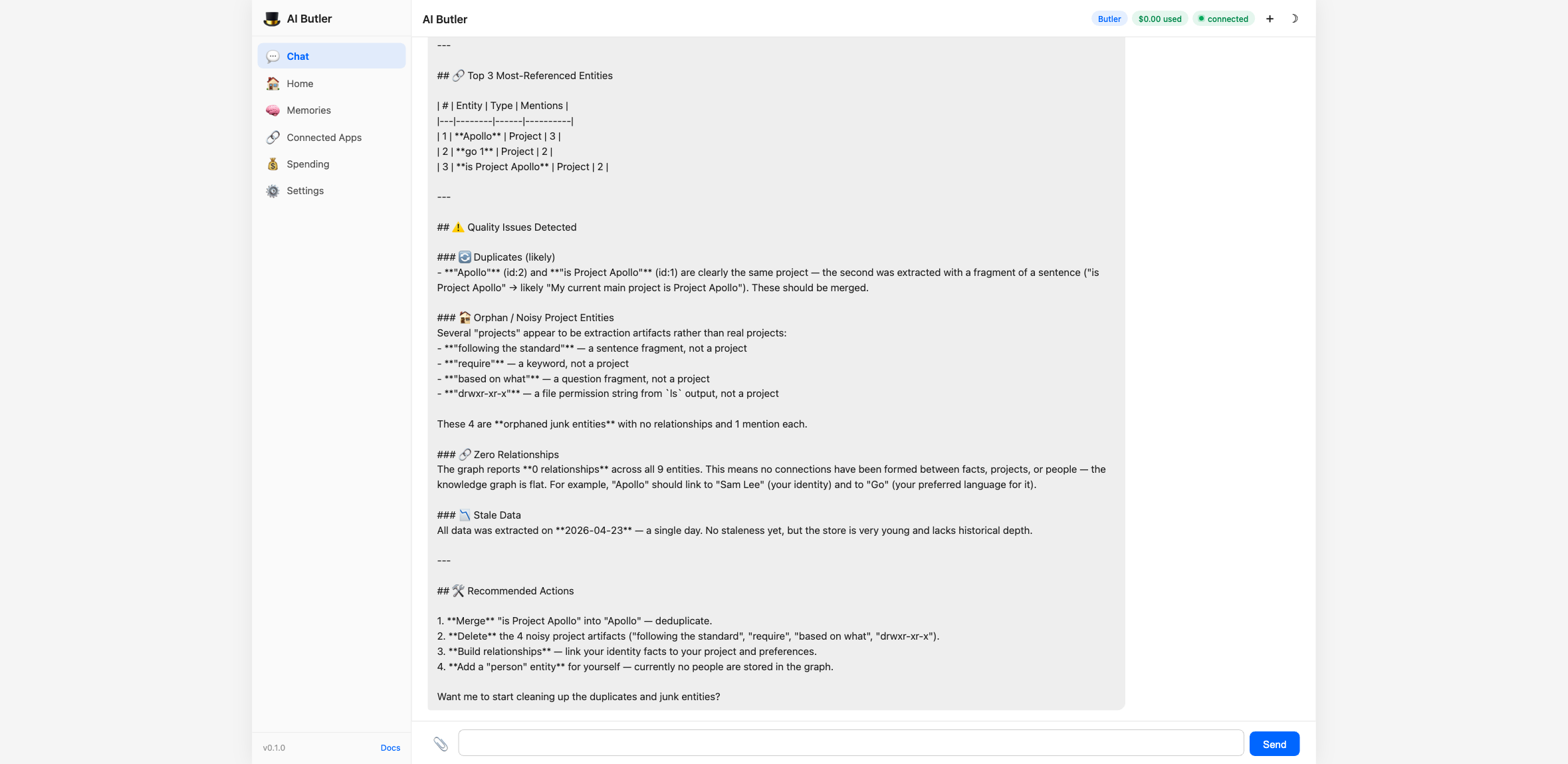
The agent flagged four real quality issues:
- Duplicate identity —
SLandSam Leeare stored as separatePersonentities; they should be merged - Stale preference — an old entry says Go is the user’s favorite language, but a newer entry says Rust; they conflict
- Orphan node — the
Project Apolloproject has one observation and zero relationships, probably abandoned - Missing embeddings — zero vector embeddings stored, which means semantic search is currently keyword-only (works, but missing a layer)
And then offered to fix them. This is memory with agency, not just a passive data store. The same tools you use to query memory can also audit it, merge duplicates, and repair orphans. It’s the database treating itself like a first-class entity.
What just got demonstrated
Section titled “What just got demonstrated”| Layer | Example above | Tool called |
|---|---|---|
| Key Facts | — always active, injected into prompts | (implicit in prompt composition) |
| FTS5 full-text | Example 2 matched “database” against the stored decision via BM25 | memory.search (fts component) |
| Knowledge graph | Examples 1, 3, 4 — entity creation, edge traversal, path-based answers | memory.graph, memory.people, memory.facts |
| Vector embeddings | Example 2 matched “architecture choices” semantically to the decision | memory.search (vector component) |
| Hybrid ranking | Example 2’s answer came from RRF fusing all three rank lists | memory.search (top-level entry point) |
| Integrity & audit | Examples 1, 5 — discrepancy detection and orphan/duplicate flagging | memory.stats + LLM reasoning over the raw graph |
Memory tools reference
Section titled “Memory tools reference”Every tool is capability-gated under memory.read or memory.write and logs to the audit trail. The agent picks which to call based on your natural-language question — you never name them explicitly unless you want to:
| Tool | What it does | Capability |
|---|---|---|
memory.capture | Save a fact, note, or decision with entity extraction | memory.write |
memory.search | Hybrid search (FTS + graph + vector + RRF) across all memory | memory.read |
memory.fts_search | Keyword-only FTS5 search for exact-match queries | memory.read |
memory.facts | List stored key facts, optionally filtered by category | memory.read |
memory.people | Query known people and their relationships | memory.read |
memory.decisions | List tracked engineering/product decisions with reasoning | memory.read |
memory.projects | List tracked projects and their status | memory.read |
memory.graph | Traverse the knowledge graph by entity or relationship type | memory.read |
memory.stats | Return counts, top entities, and health diagnostics | memory.read |
Context compaction (when conversations get long)
Section titled “Context compaction (when conversations get long)”When a single conversation grows past the model’s context window, AI Butler compacts older messages algorithmically into structured summaries — preserving tools used, key files touched, pending work, and a chronological timeline. No LLM is used for the compaction, so there’s zero cost and zero hallucination risk.
The compacted summary is inserted as a system message at the top of the next turn, and the original messages are kept in the session transcript store (and thus in FTS5, the graph, and the vector index). You lose nothing — compaction is a rendering optimization for the model’s context, not a data deletion.
Optional LLM-assisted enhancement is available for users who want richer summaries and don’t mind the token cost; it’s off by default.
What makes this different from ChatGPT’s “memory”?
Section titled “What makes this different from ChatGPT’s “memory”?”A common question: “Doesn’t ChatGPT also have memory now?”
Sort of, and the differences matter:
| Property | ChatGPT memory | AI Butler memory |
|---|---|---|
| Where it lives | OpenAI’s servers | Your local SQLite file |
| How retrieval works | LLM reads a snippet list injected into context | Real database query (FTS + graph + vector) |
| Hallucination risk | Non-zero (LLM reconstructs from compressed text) | Zero (search returns exact stored content) |
| Cross-session depth | Shallow, occasional retrieval | Every turn has the full graph available |
| Graph traversal | ❌ | ✅ (recursive SQL over entities + edges) |
| Multi-channel shared memory | ❌ (one app, no Telegram/Slack/terminal) | ✅ (web, terminal, Telegram, Slack, Discord all share one store) |
| Capability to audit | ❌ (you can’t see or query the storage layer) | ✅ (memory.stats, memory.graph, direct SQLite access) |
| Export/backup | ❌ | ✅ (cp ~/.aibutler/aibutler.db backup.db) |
| Works offline | ❌ | ✅ (with Ollama) |
The headline difference: ChatGPT’s memory is a feature they bolted on. AI Butler’s memory is the architecture of the whole product. Every other feature — scheduling, channels, plugins, swarm, MCP tools — is built on top of it.
Architecture details (for the curious)
Section titled “Architecture details (for the curious)”- SQLite via ncruces/go-sqlite3 — pure-Go WASM build, zero CGO, FTS5 and recursive CTEs included
- FTS5 uses BM25 ranking with trigram tokenization; index is rebuilt incrementally on every write
- Entity extraction is rule-based first (regex + POS-tagging for common patterns), with optional LLM-assisted extraction for complex decision records
- Knowledge graph is two relational tables —
entitiesandentity_relationships— queried via recursive CTEs for multi-hop traversal - Vector search uses a pure-Go
vec_distance_cosinefunction registered via SQLite’s custom function API; embeddings are stored as BLOBs in amemory_vectorstable withUNIQUE(source_type, source_id)to prevent duplicates - Embedding provider is auto-detected: Ollama’s
nomic-embed-textif running locally, else OpenAI’stext-embedding-3-smallif an API key is set, else embeddings are disabled and the system falls back to FTS + graph only - Reciprocal Rank Fusion combines rankings from the three search sources with the standard formula
score(d) = Σ 1/(k + rank_i(d))usingk=60
The full implementation lives in internal/memory/ — see fts/, entity/, graph/, vector/, and hybrid/.